何凯明的从表征学习到深度学习发展进程视频学习笔记
之前囤积的很多 Read it later 里面有何凯明 入职 MIT 之前的 unpaid 课程介绍。一直挂在 Chrome 浏览器那里,想着啥时候看,今天不知咋的想着看看吧,不然就关掉了。幸亏看了,大佬讲的真是的行云流水,娓娓道来。
从 LeNet 到 AlexNet 到 VGG Nets 到 GoogleNet 到 normalization/initialization module 到 ResNet 到 RNN/1-D CNN 到 Transformer 以及应用 GPT/AlphaFold/ViT ,这里记录下每一步关键节点的意义以及作用。可以很清晰的看到深度学习技术的一步一步发展过程出现的问题,以及对应的解决方案。
关键节点
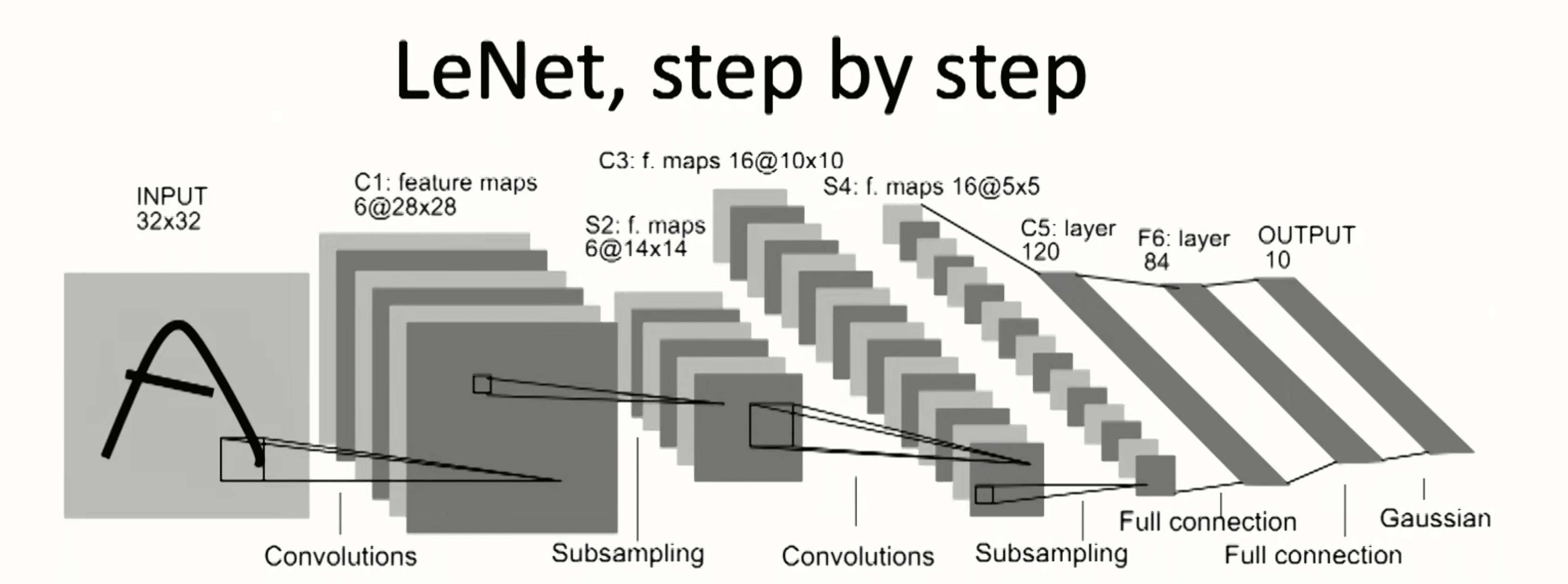
1989-LeNet
具备了 DNN 的基本雏形:卷积(5x5)/下采样/全连接层/输出层,但是受限于算力和高质量数据的约束,这个技术就被雪藏了 20 年,,,
2012-AlexNet
引入了 ReLu 替换了原来的 Sigmoid 以及 Dropout 来让网络可以更深,以及 data augmentation 的作用
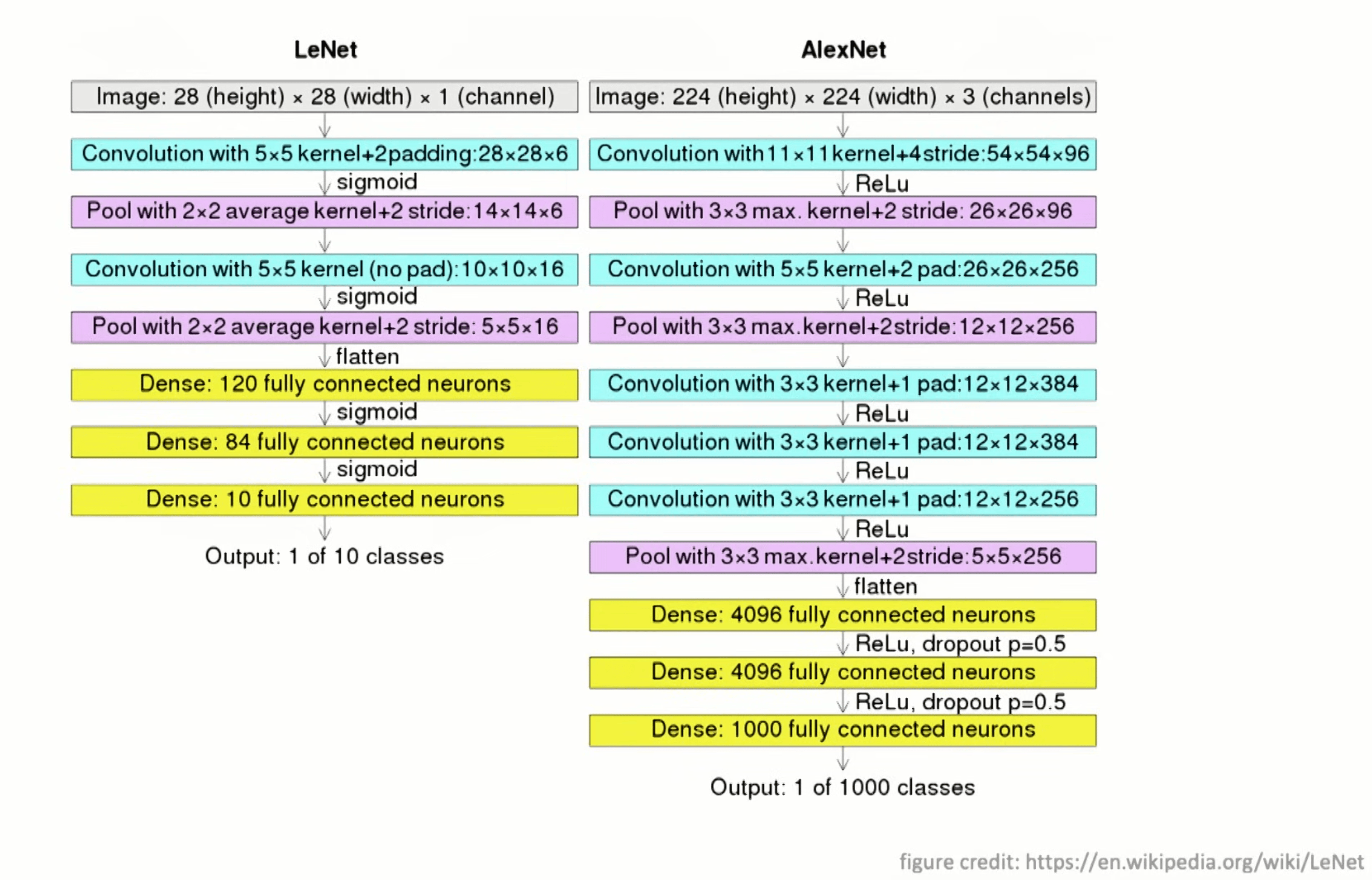
注:后续的量化方法其实和 Dropout 作用上有些类似,也可以更好的让网络泛华,不至于过早过拟合;且在这之后,对网络的可视化让大家觉得这条路是对的。
2014-VGG Nets
证明网络越深越好,并且采用统一的 3x3 卷积,并且在用 stack 逐层添加的训练方法来训练更深的网络,也引出了后续对初始化方法的研究
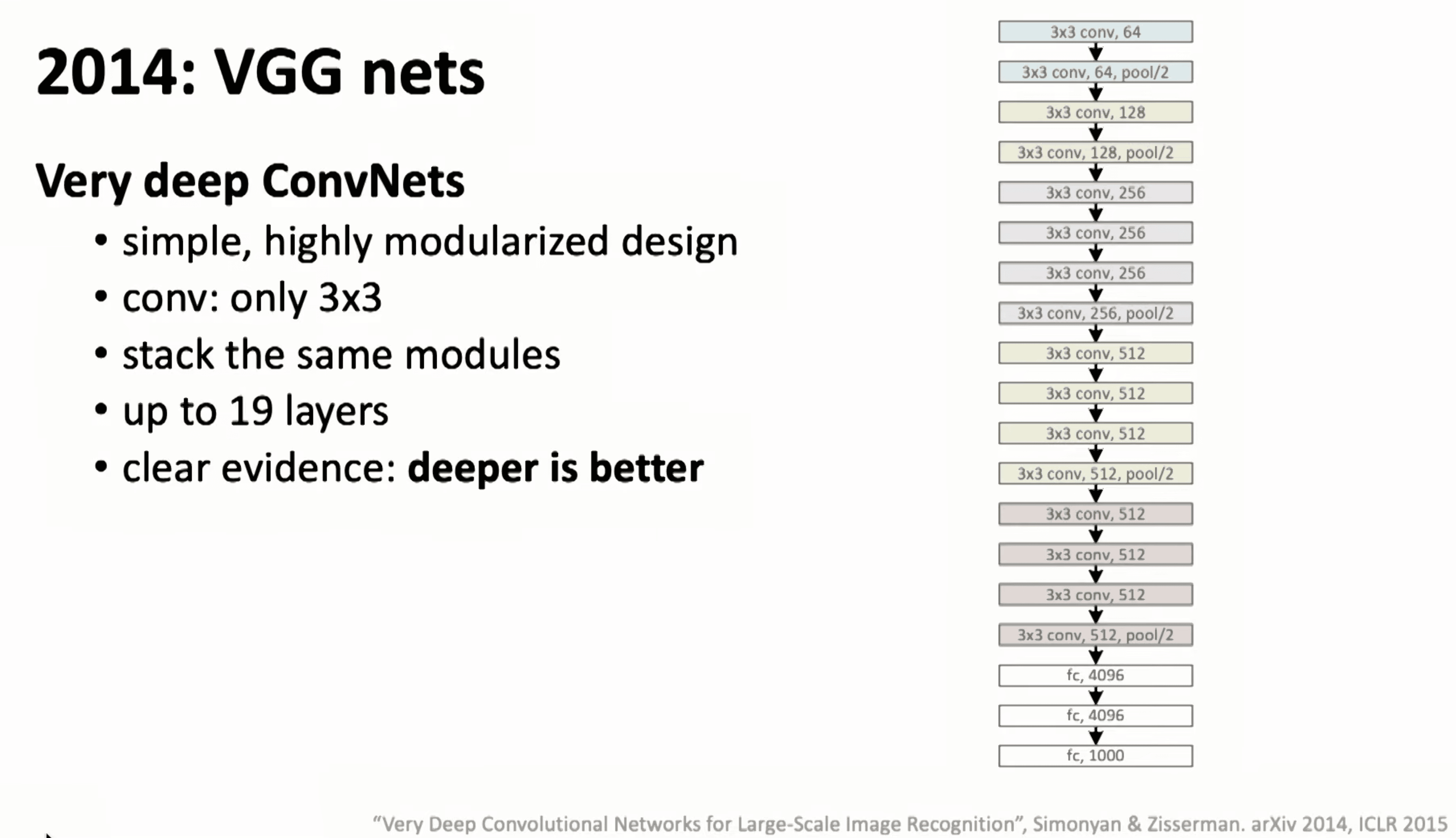
注:更深的网络,开启了预训练的时代,也就是迁移学习思想的落地,可以在无标注上进行大规模学习后,其特征表示可以签到其他类似原理的应用场景。
2014-GoogleNet
引入了 1x1 网络模块,相当于一个直连的捷径,也开发了同层不同方式的横向组合阶段,但是破坏了网络设计一致性的哲学,也给初始化方法带来了适配挑战。
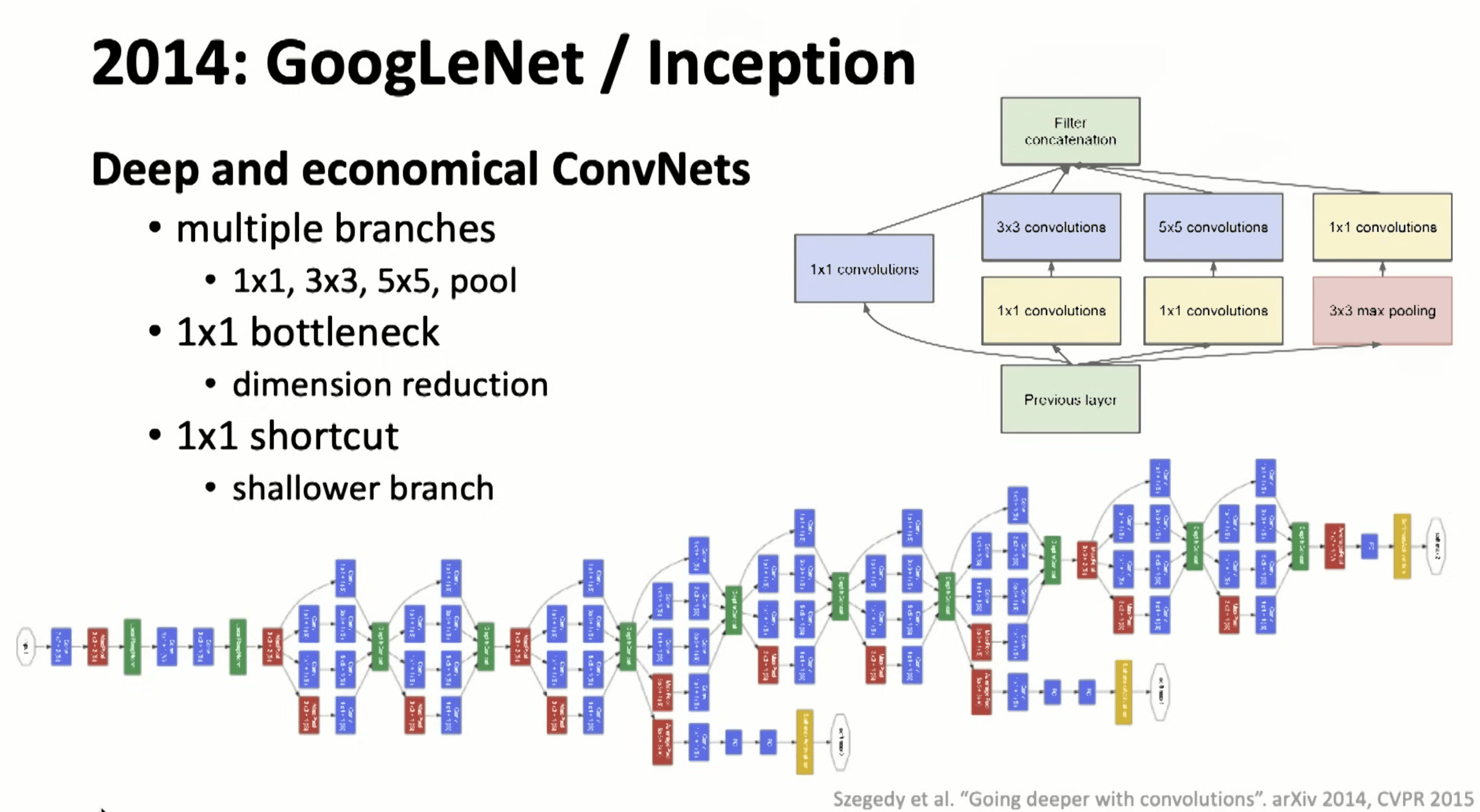
注:这个捷径和后续 ResNet 的作用类似,不知道有没有受这个的启发。
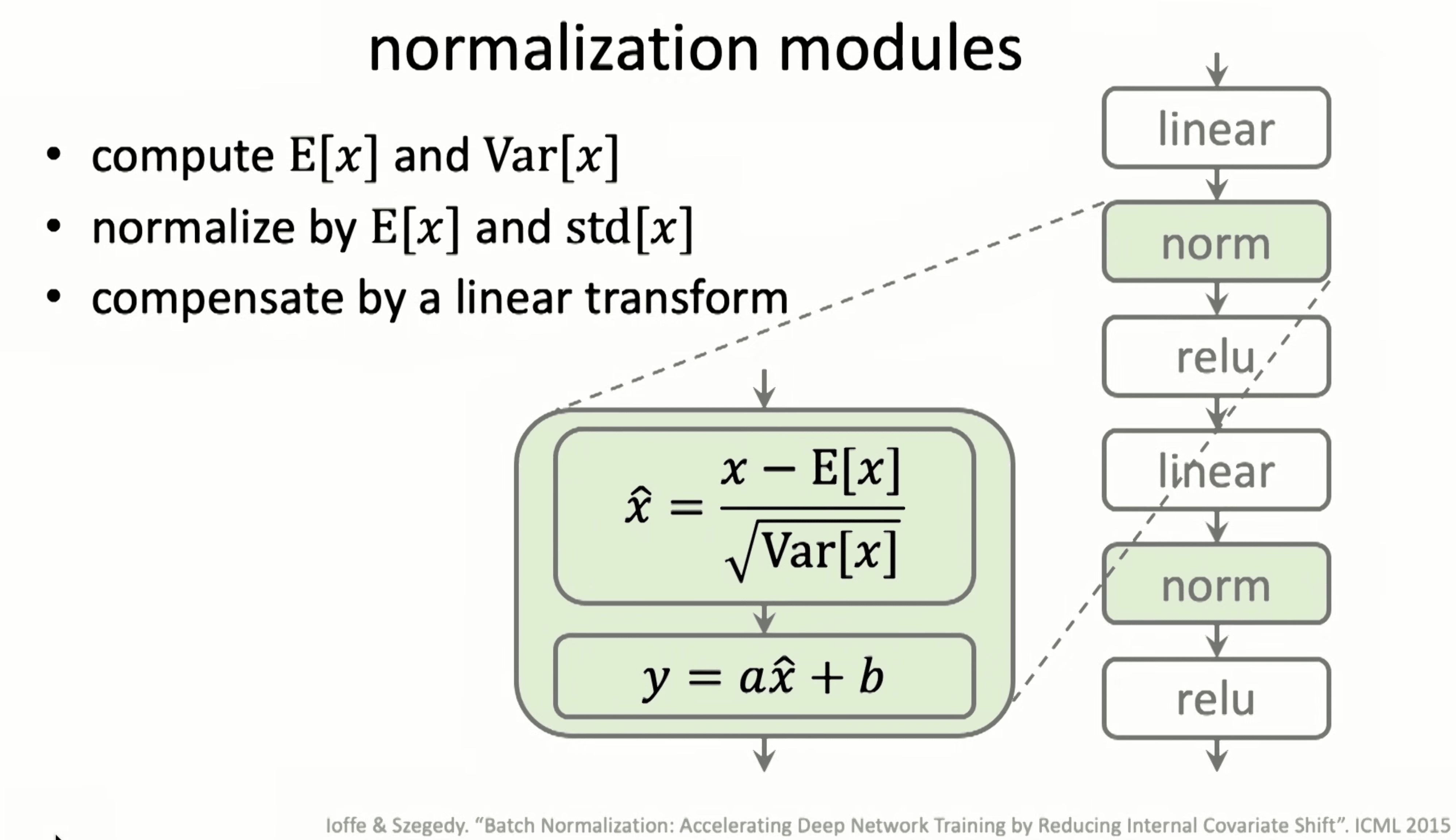
normalization/initialization module in deep learning
网络越深会进入梯度爆炸或者消失问题,需要一个比较好的初始化方法,因为一个简单通用的模块,在网络的每一层添加一个归一化可以让网络越快收敛但是又不会陷入局部最优解,也就是会有更好的结果。其中又以 batch 和 layer 归一化方法最为普遍和好用。
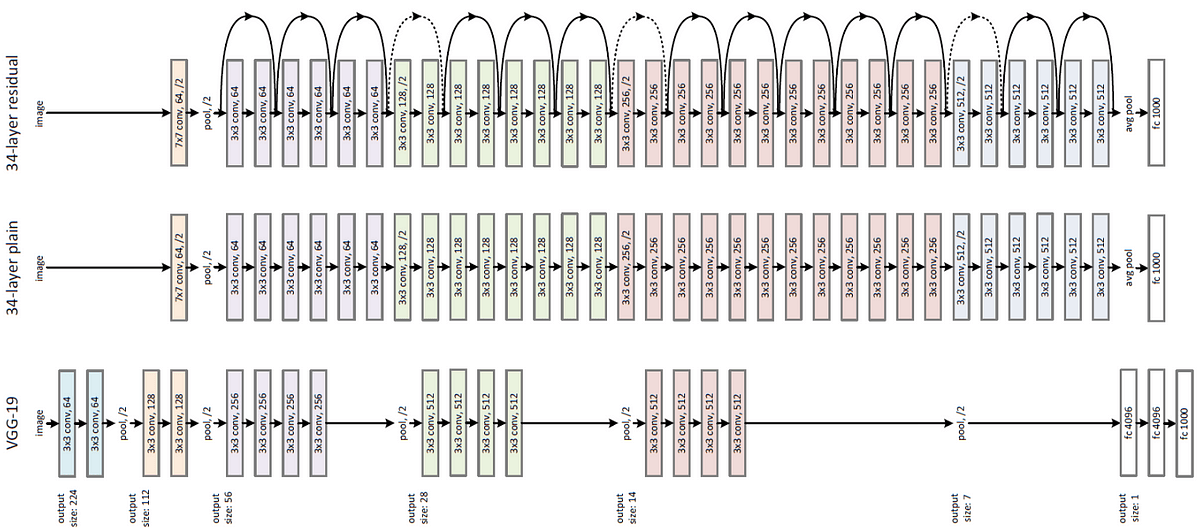
2015-ResNet
在网络超过 20 层后,发现再继续深层会导致连训练都开始下降,引入 F(x)=H(x)+x 这样一条线,让网络可以更深后不至于性能下降

注:这个真的又简单有好用。
RNN for sequence modeling
RNN以及后续的 LSTM/GRU 相当于时间局连接【相比于 CNN 的空间局部连接】,只是和当前时间输入以及前一个输出连接,其在训练上非常不友好,因为需要依赖前一时刻的输出。
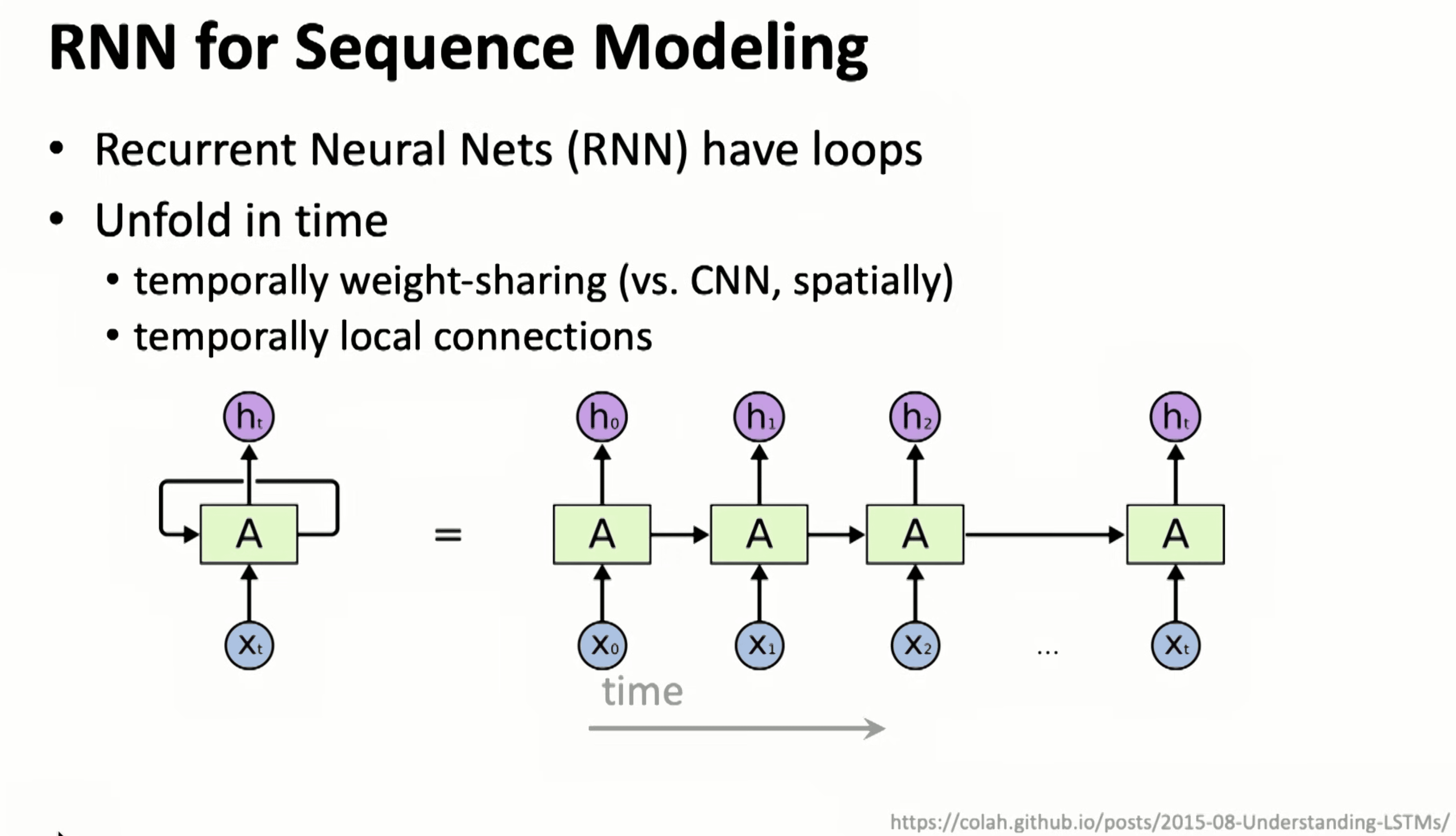
注:RNN 上迭代出来的 LSTM 则稍微优化了下 RNN 相乘导致的快速梯度消失或者爆炸问题,但是还是无法支撑较长的记忆;GRU 则优化了 LSTM 的计算复杂度,基本可以说是平替。
1-D CNN for sequence modeling
如果采用 1-D CNN 的来进行时间序列建模,则可以让训练并行,但是模型的当前节点需要不能依赖未来的输入,且 kernel 的长度决定了感受野的范围,如果通过多层增加范围又会让模型急剧扩张,且也无法感知长久的时间
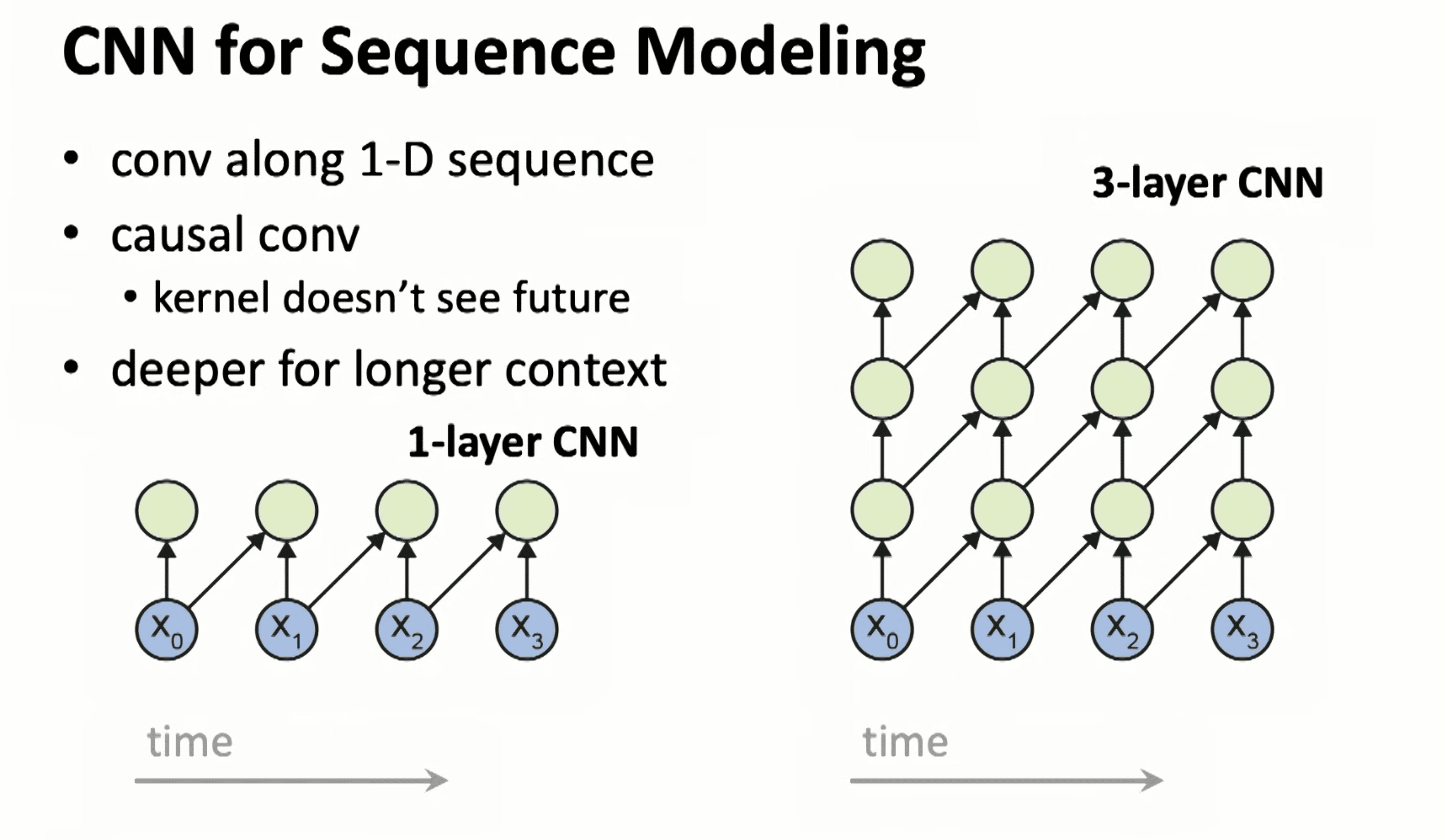
注:TNN 就是 1-D CNN 的演化结果。
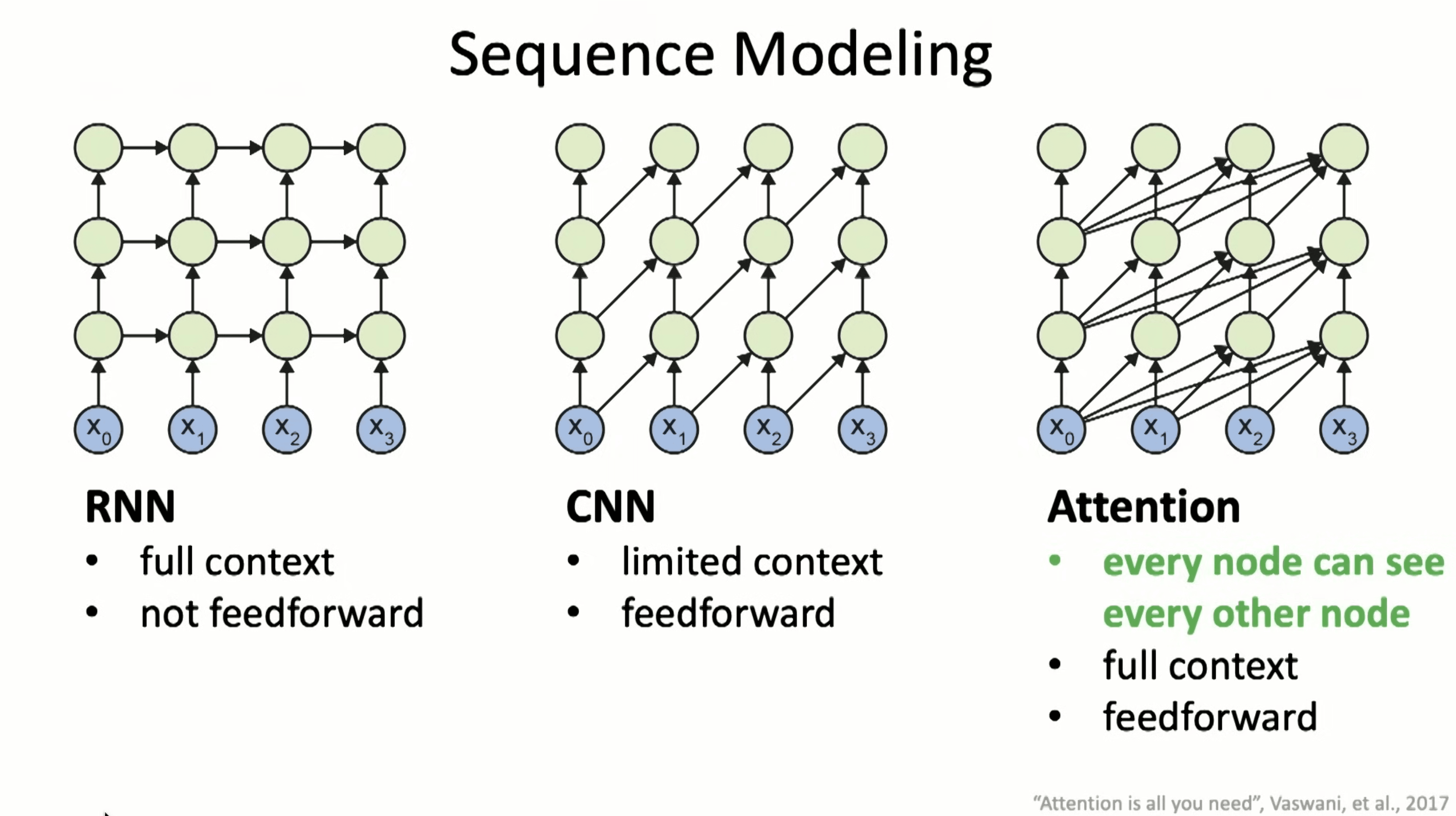
RNN vs. CNN vs. Attention
可以看到 RNN 只依赖当前时间输入以及前一模块的输出;CNN 则依赖历史状态以及当前时间输入;Attention 则是一个更加通用的 CNN,可以在当前节点直接感知历史更多作为输入。
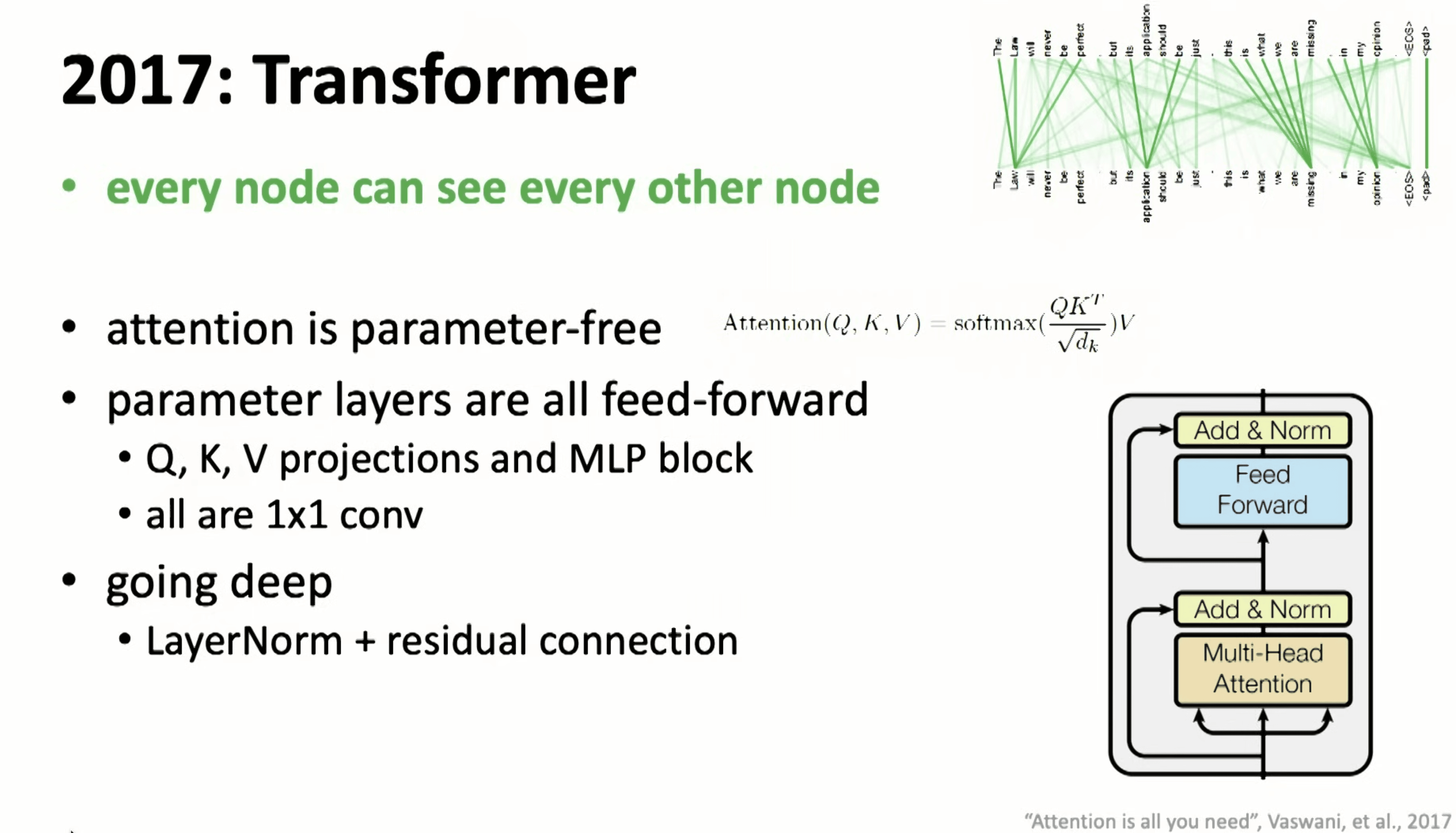
2017-Transformer
集大成者,开启了个时代!
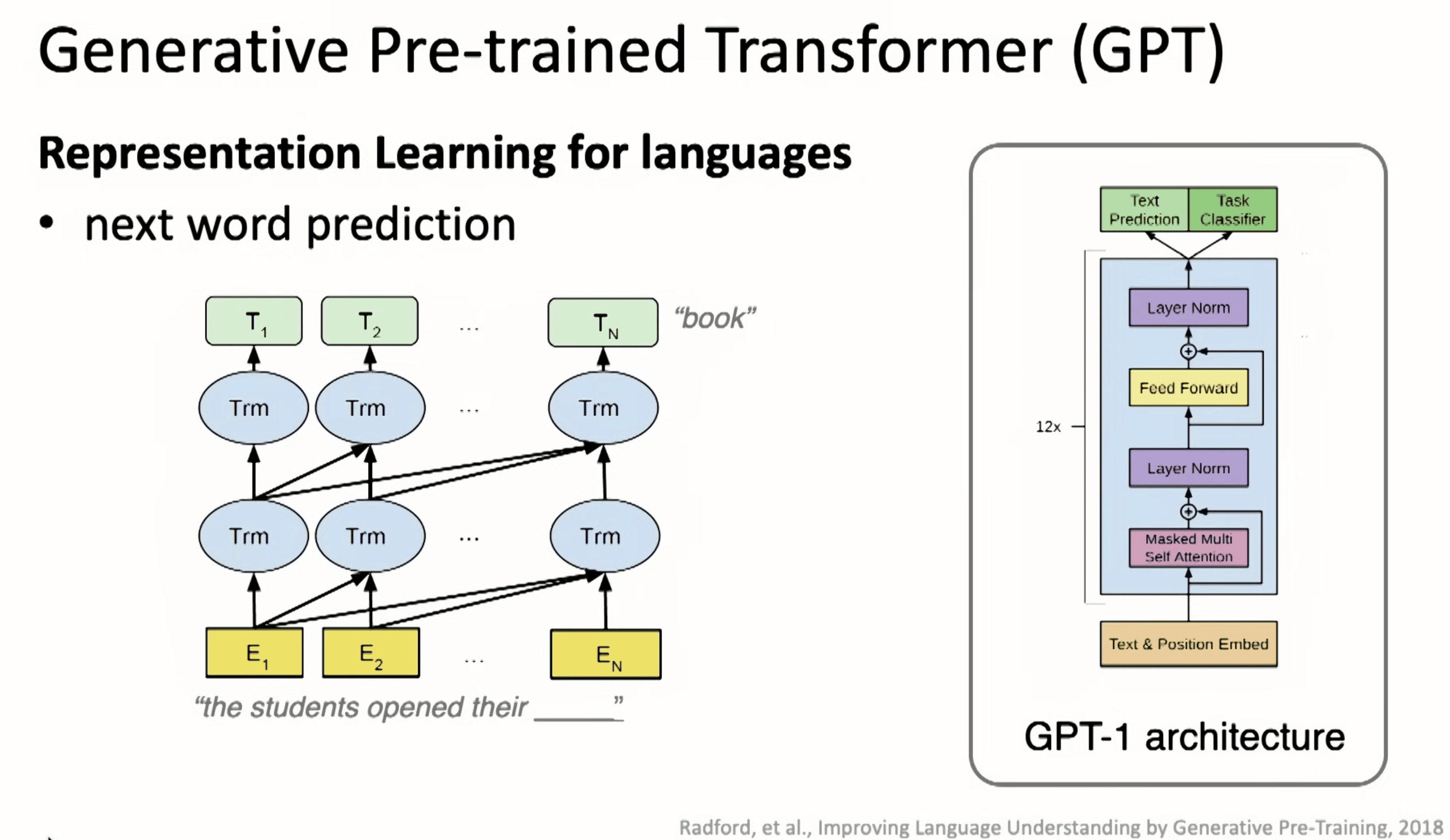
2018-GPT
Transformer 在语言领域的应用,被称为 GPT 时刻。
2021-AlphaFold
在生物蛋白质序列也可以学习到蛋白质的表征。

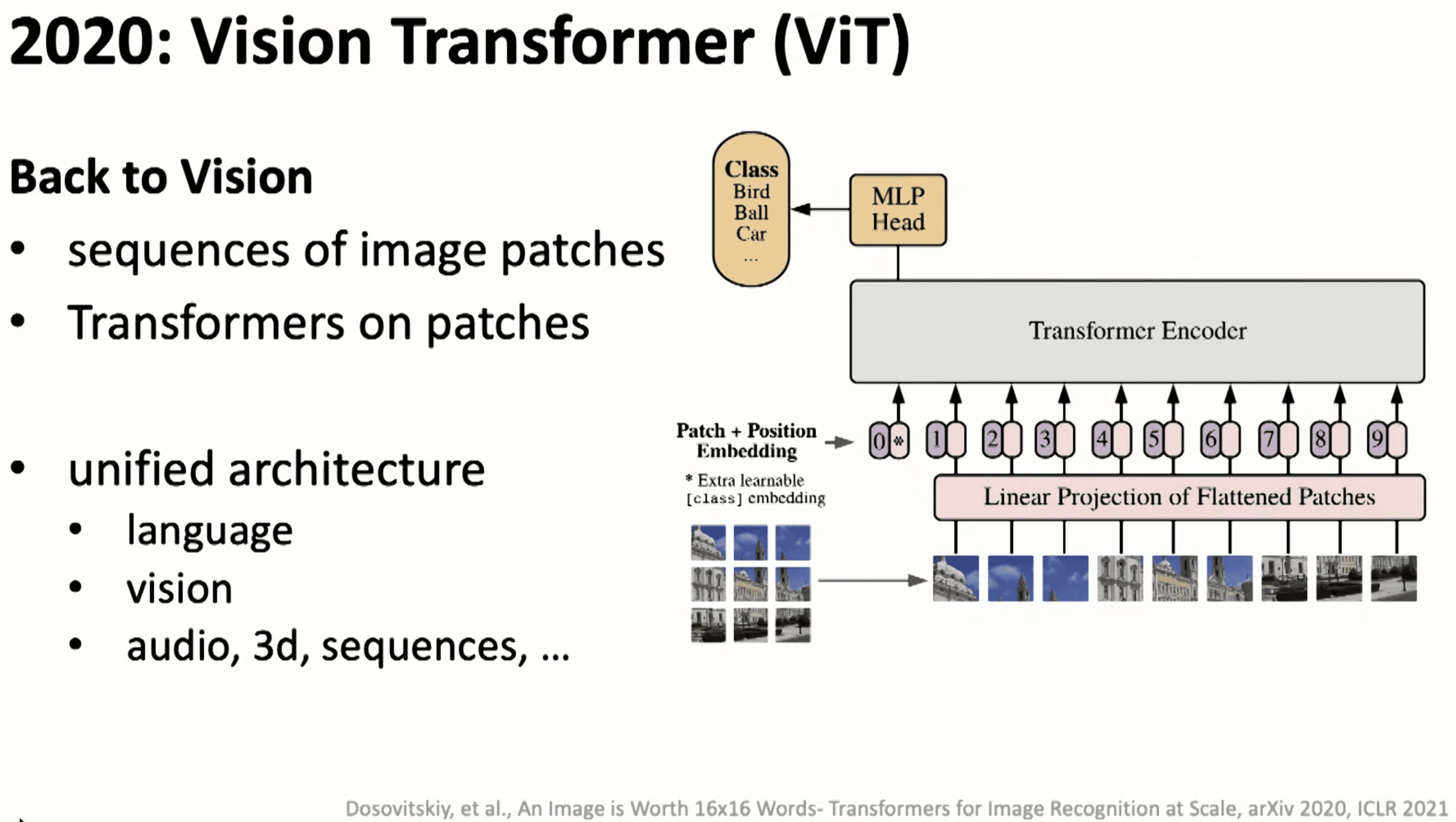
2021-ViT
并且在视觉领域也可以用 Transformer 进行表征学习的方法统一。